Parsing the parser
This blog is about my project called yacv. If you have no idea what that is, you should watch the video. In this blog I go through:
- Why I find parsing interesting
- Why I find parser generators to be amusing
- Why and how I built
yacv - Interesting facts and references about parsers. You can skip down to this part directly
Parsing is a very fundamental process in computer science. It comes up pretty much everywhere in computer science – be it writing a simple command line program (which accepts and hence “parses” command line arguments) or be it building a complicated client server architecture (which will most likely use message passing and hence will need “parsing” the message)
Parsing is awesome
At my college, parsing is taught in compiler construction class – in the very final semester of the degree. Because of this I wasn’t getting any theory (as in theoretical CS) related stuff in the very awesome “dragon book”. Due to COVID lockdown, I finally got time to revise theoretical CS again. After revision, I was just amazed how powerful the concepts in theoretical CS can be. I was also flabbergasted by the importance of parsing
The heart of “compiling a program” is parsing – in a way, once you have the parse tree, you’re “pretty much” done !
- Once you get the parse tree, you’re sure that this program was syntactically correct (user hasn’t inputted a Python code into a C compiler)
- Using the syntax tree, you can VERY EASILY identify semantic errors (without a syntax tree, this is a guaranteed nightmare)
- Syntax directed translation can generate machine code for you ! (granted this code won’t be optimized in the slightest)
- Code optimization heavily relies on several structures and properties of syntax trees
I mean ofcourse, it makes sense. There’s a reason parsing is in the first few steps of compilation pipeline. But I finally had the “aha, this makes so much sense” moment so I had to write it here. The entire compiling process is in a weird-way “just” parsing. You can just have syntax directed translation to generate you machine code which works ! Ofcourse, such a code will not have any safety checks or optimization whatsoever, but in theory it just works !! How cool is that !!!
In reality though, many people (including myself) would care about (boring) things like memory safety and (cool) things like code optimizations. But still, even then, you’re just adding things on top of parsing to make things better
Why do parser generators exist ?
Building a parser is no easy task. Making sure that parser works correctly for ALL the strings that can be possibly be input to the parser is a tricky task. For finite languages, this is very easy as we simply try all the possible strings in the language with the parser and verify that parser outputs “yes” for all the strings in the language
On infinite languages i.e. most practical languages, this is impossible to do for obvious reasons. On the other hand, if we use some properties of formal languages, we can automatically generate the parser which will be guaranteed to work
Let’s take an example language \(L = a^nb^n\). If we were to write a parser for this in C, it would look something like this :
1
2
3
4
5
6
7
int is_valid(char *s, int n) { /* String `s` with length `n` */
int i = 0, count = 0;
while(i < n && s[i++] == 'a' && ++count);
/* At this i, s[i] != 'a' and count = count(a) */
while(i < n && s[i++] == 'b' && count--);
return count == 0 && i == n-1;
}
It will work and because the language is so easy to understand, we can easily verify if this parser will work correctly or not. But in case of practical languages, this is often an impossible task to do so. So how can we make sure that our parser works correctly for all strings in a language ?
To be sure about this, we must know all the possible prefixes of strings in a language. A parser algorithm can then just read the string one by one and make sure the prefix (i.e. string read so far) belongs to one of the possible prefixes. If at any time, this string is NOT a possible prefix, we quit and say “invalid string”. Formally, these prefixes are referred to as “viable prefixes”
But then, we have just moved the problem from “knowing all the strings” to “knowing all the prefixes”. Thankfully, for context free languages, language formed by all the prefixes of that language is a regular language. This means that we can generate a regular i.e. finite automata for identifying viable prefixes of a language. This is precisely what a parser generator does – it generates the automaton of viable prefixes given the context free grammar and uses it to “parse” the input string. This regularity in prefixes is also the reason why parser generators exist only for context free languages !
(BTW, the approach I’m discussing here is called “bottom up parsing” and the specific algorithm is called “LR parsing” – which was presented by Donald Knuth. There is also an approach called “bottom up parsing” but it does not allow very interesting parser “generators” so I’m skipping that here)
Key takeaways
- Parsers are awesome !
- Parsers (often) rely on finding viable prefixes
- Writing and testing parsers can be very difficult
- Parser generators can generate a parser that works perfectly for a given grammar
- Parser generators exist only for context free grammars because prefixes of only context free languages form a regular language
yacv: Yet Another Compiler Visualizer
All the hardwork I had to go through to understand parsers made me realize that there are going to be tons of people like me around. What made parsers “click” to me was this amazing LR(0) parser visualization by Zak Kincaid and Shaowei Zhu which walks you through the parsing process step-by-step. Other tools such as JSMachines also helped. But none of these tools produced output which was “presentable” (i.e. can be put in presentation) So I wrote a small tool that visualizes parsing procedure using manim – an animation library by 3Blue1Brown. The name yacv is inspired from old parser generator software called yacc (Yet Another Compiler Compiler)
Approach
Typical parsers (like LR and LL) read input stream one character at a time and keep building a partial parse tree until the input stream ends. At the end, the parse tree is (hopefully) complete and can be used further. In yacv, I progressively build a simple python \(n\)-ary tree structure as I am parsing. Later I use GraphViz to lay out the tree visually. This simplifies the programming and enables me to add as many parsers as I want to yacv

Graphviz Conversion
Converting the abstract syntax tree to graphviz graph was simple. Just creating the graph with the specification was simple enough. But that graph did not look “nice” for 2 reasons:
- The leaf nodes i.e. the terminals in the string were on various different levels
- Nodes on the RHS of the production weren’t on the same level
- All productions looked the same color
| Before | After |
|---|---|
 |
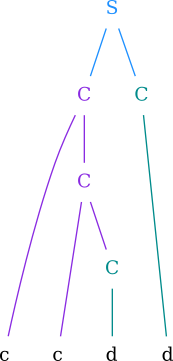 |
To get this transformation, I had to store the production number at every node of the tree and use a lot of “rank hacks” in graphviz. Storing production ID at every node is a bit awkward because then you have to maintain some order of the productions. I figured the order in which they are present in the input file was the best. Then we can simply map production ID to a color (which is also customizable by user). I used pygraphviz for doing all the GraphViz stuff. It provides good enough control on the GraphViz graph you are creating despite being just a SWIG wrapper. One of the most valuable function for me was the layout function. Layout function will hardcode the position of each and every node using the specified rendering algorithm. This simplified interfacing with manim a lot
Putting everything in a manim frame
This has to be the most frustrating part of the project. First, there is no reliable documentation for manim whatsoever. There are 2 versions of manim – a community version called ManimCE and original version (by 3b1b) which uses OpenGL now. I had used manim once or twice before starting this project but not so much that I knew everything in and out. Thankfully, there is a series of excellent tutorial videos on YouTube channel called Theorem of Beethoven
The TL:DR of the tutorial was that everything in Manim is managed on a 14x8 grid. This meant that I had to resize my GraphViz graph to fit into 14x8 grid. Thankfully, layout() calculates the coordinates of each and every node so positioning nodes on the manim grid wasn’t a problem at all
About edges, GraphViz stores every edge as a Bézier curve (makes sense because GraphViz often renders to SVG). Finding this information took a lot of digging through GraphViz code, but it was worth it because I learned a lot about SVG and Bézier curves. Storing a Bézier curve usually means storing the control points, then at the time of rasterization, we can render \(n\) points on the curve using these control points. To put them in manim, I decided to render fixed \(n=100\) points on every edge in their original coordinates and then rescaled every point down to 14x8. Then using this list of points, I used a VMobject from manim and used add_points_smoothly method to add all these points into that object. All of this implementation is tied together in a new Mobject class called GraphvizMobject code for which is available here
Animating between steps
Using simple manim transform on every node and edge wasn’t enough. It looked awkward with nodes flying everywhere

To make the animations smoother, I had to relabel the GraphViz graph carefully, then map every node ID from GraphViz graph to an Mobject and then while transforming, use the node IDs to smooth the animations. The code for the animation speaks for itself better than I can

Final outcome
After the key components were working nicely together, I decided to sweeten the animation by adding visualization for the parsing stack as well. This was significantly easier than GraphViz although it needed some neat little tricks as well. Main obstacle in animating this was the size of stack during parsing. It is completely possible that stack contains 100s of elements during parsing at a time and it was very difficult to animate this. So I had two options when implementing stack animations:
- Resize every element in stack once new element is added (so essentially font size of character decreases to accommodate new stack elements)
- Show only top-\(k\) stack elements and then show “\(\dots\)” at the end to indicate more elements are present
I went with the second option because it looked clean and I didn’t have to worry about dynamically resizing every single element in the stack. Animating these stack states was a cakewalk after animating GraphvizMobjects
Finally, I decided to package everything in a nice python package so everyone can access it without worrying about the implementation. This project was an insane rollercoaster ride. I doubted my tool choices at many times, I doubted in myself many times but at the end it was a really good learning experience. Check out yacv on GitHub or read the docs